Intro to IRT
Aiden Loe
07 January, 2021
This page provides a broad overview of IRT. In time, I will create more specific content that talks about each area in greater detail. Please email me if you notice any problems. I can be reached at bsl28@cam.ac.uk
Assumptions of IRT
In short, there are 4 assumptions of IRT.
Monotonicity (Shape of curve)
Unidimensionality
Item invariance
Local independence
Monotonicity
Monotonicity is best displayed on a graph as if the curve look like the following below. This curve is called the item characteristics curve (ICC), which is assumed to reflect the true relationship between the trait and the responses to the item. For example, in an educational setting, what you see is that as the ability level increases, the probability of getting the item correct increases monotonicially. Within a health setting, that would mean that as the ability level incerases, the participant is more likely to endorse a higher response option for that item.

There are a few ways to test this. One way is to use mokken analysis. The mokken package can be used to test for item monotonicity.
Unidimensionality
In the context of IRT, undimensionality is assumed. That is, only one latent trait is measured by the set of items in the test. For example, all the items in the CES-D scale is a measure of the depression symptoms and nothing else. That is what it means to be unidimensional. You can use factor analysis for example to evaluate the dimensionality of the test. You can think of it graphically like the image below. All the items are meant to be measuring only a single latent trait.
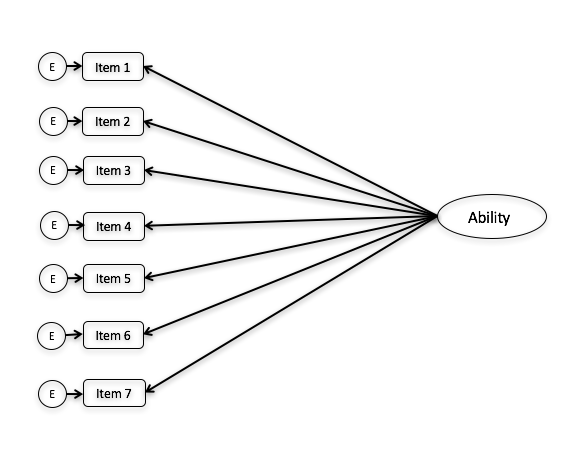
There is something called multidimensional item response theory, where a scale could measure more than a single trait. Reckase (2009) is a fantastic book on the topic of MIRT. But that is something for another day.
Item invariance
The assumption of invariance is best understood as the characteristics of the item parameters and latent trait being independent of the sample characteristics within a population. That means, for an item such as “I do not cry often”, the item parameters estimated by an IRT model would not change even if the characteristics of the patient, such as age or gender, changes. Under IRT, the ability of a person under measure does not change due to sample characteristics. Differential Item Functioning (DIF) analysis is often used to evaluate if this assumption if violated.
Here is how two types of DIF looks like:
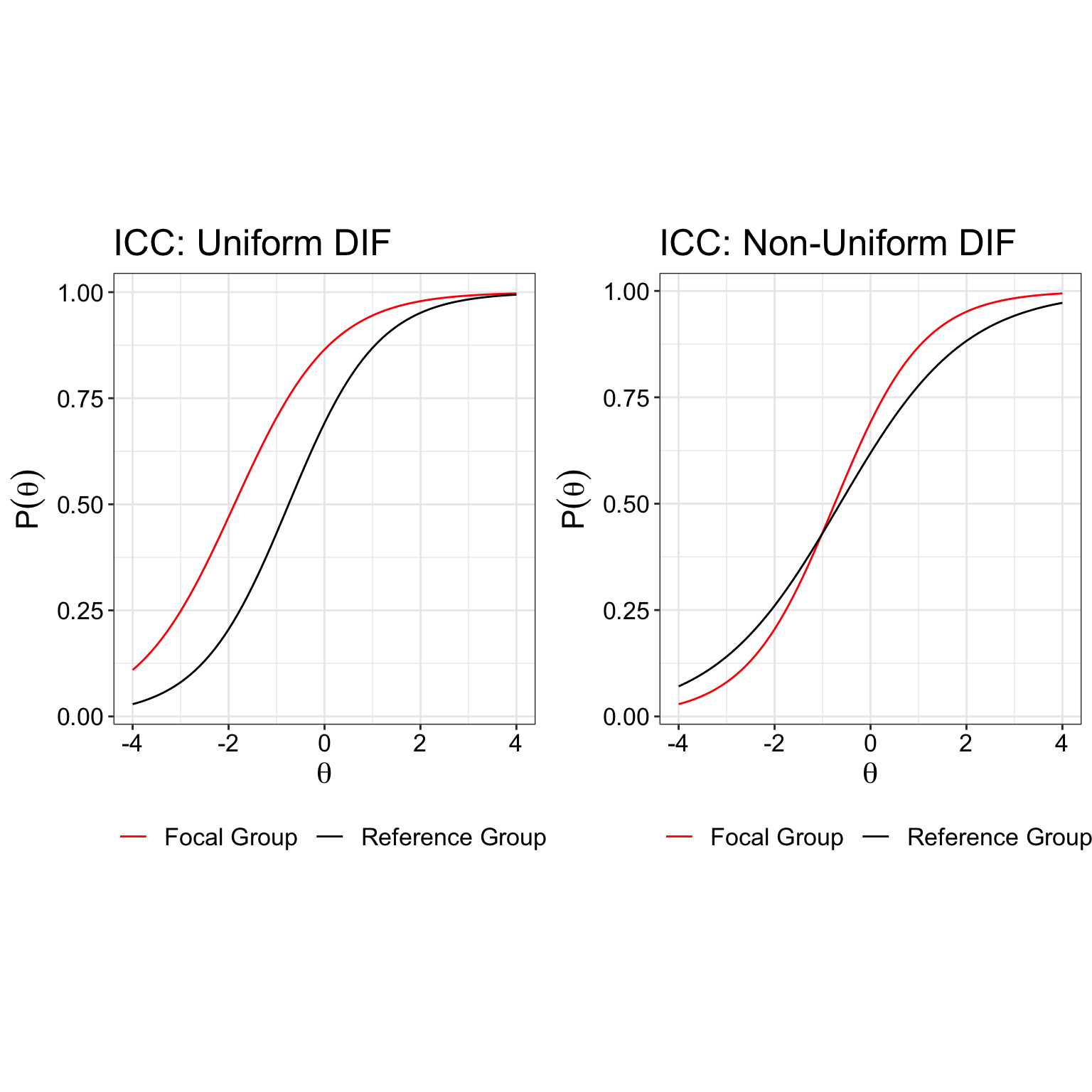
Ideally, you want both curves to be together rather than separated in order for the assumption of item invariance to hold.
Local independence
Under the assumption of local independence, the participants responses are not statistically related to each other, before and even after the latent trait is taken into consideration. There are two situations where local independence may appear: (1) where negatively worded items are included in the scale. (2) the responses of one item influences the way participant responses to another item. Some solutions to resolve these problems are:
Simplify the wording of items
Decrease the number of items
Limit the response options.
Properties of IRT
Several item properties are necessary to know. Namely, the properties are that estimated based on IRT models.
Discrimination(\(\alpha{_i}\))
Difficulty(\(b_i\))
Guessing(\(c_i\))
Inattention(\(d_i\)) parameter.
where, i = items.
Discrimination parameter (\(\alpha{_i}\))
The discrimiation parameter is aka the \(\alpha{_i}\) parameter. It is used to determine how well the items discriminate against different levels of the latent trait. In this case, ranging from -4 to 4. The \(\alpha{_i}\) parameter other name is the slope parameter. Steeper slopes at particular level of the traits indicate that it is more discriminative than levels of the traits with gentler slopes.
So if you just look at the green item, it is most discriminative between -2 to 0, and it is least discriminative between -4 to -2 and 0 to 4. The most discriminative point is always at the centre of the curve.
In theory, the values for the \(\alpha{_i}\) ranges from \(-\infty\) to \(+\infty\). Negative values of the \(\alpha{_i}\) are possible but considered problematic as it would mean that items with increasing levels of ability are less likely to endore more severe response options. This could happen when the item poorly discriminates between levels of the ability (illogical relationship) or there was some sort of coding error.
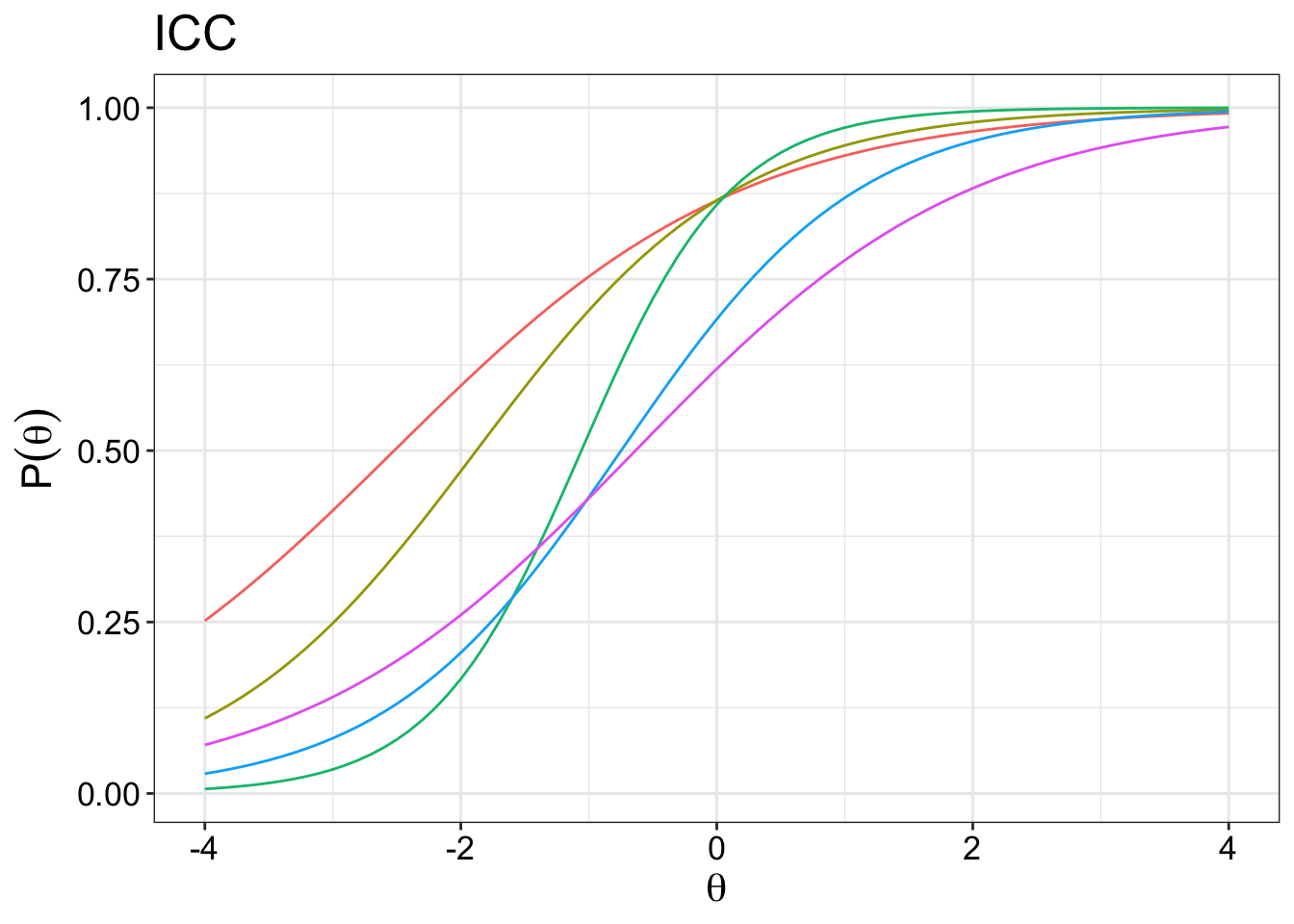
From the plot above, we can see that some items are more discriminating than others. For example, it is clear that the green item is the most discriminating item because of the steepest slope it has compared to the other items. Arguably, either the red item or the purple item would have the gentlest slope. This has to be confirmed emprically of course.
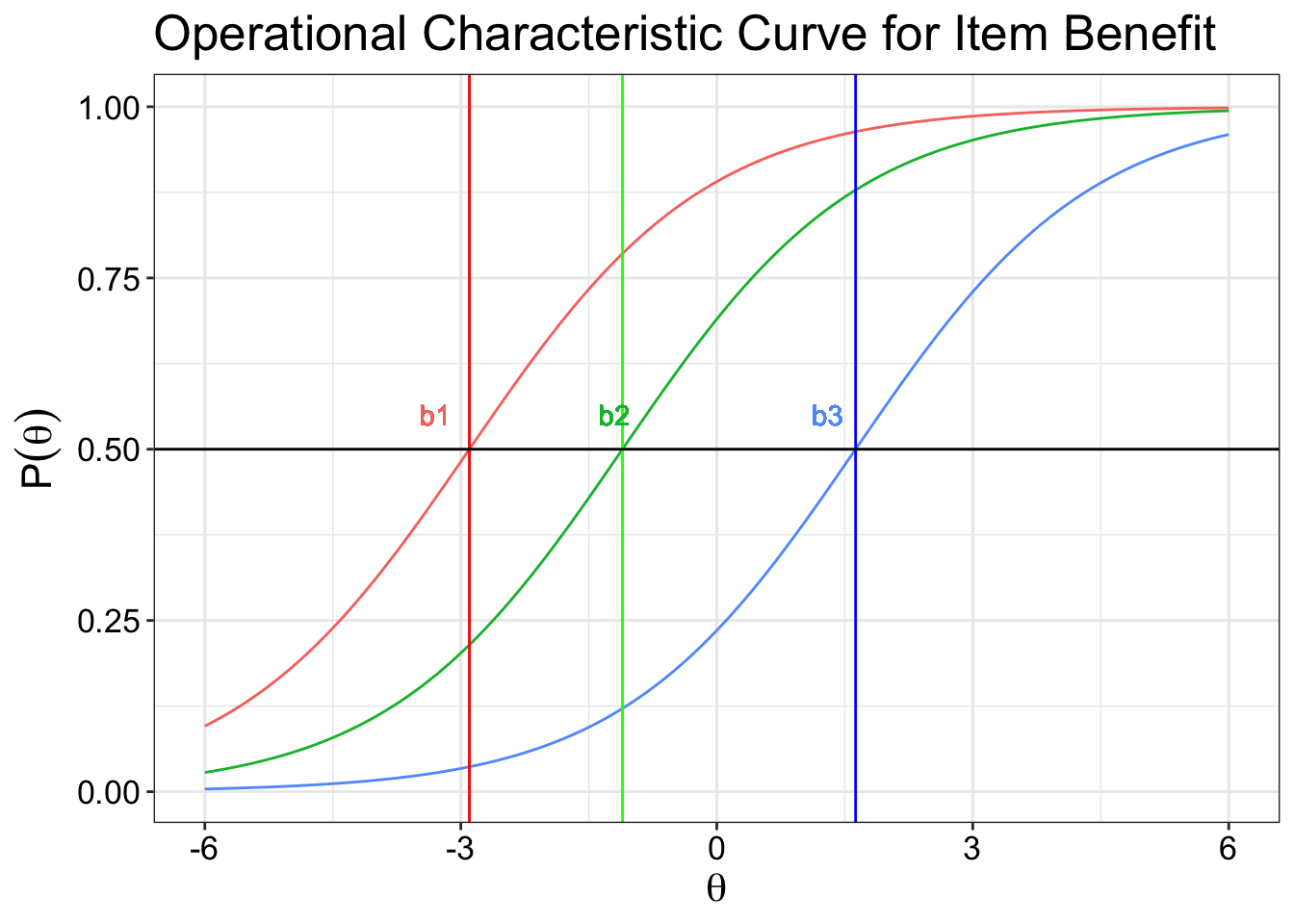
Difficulty parameter (\(b_i\))
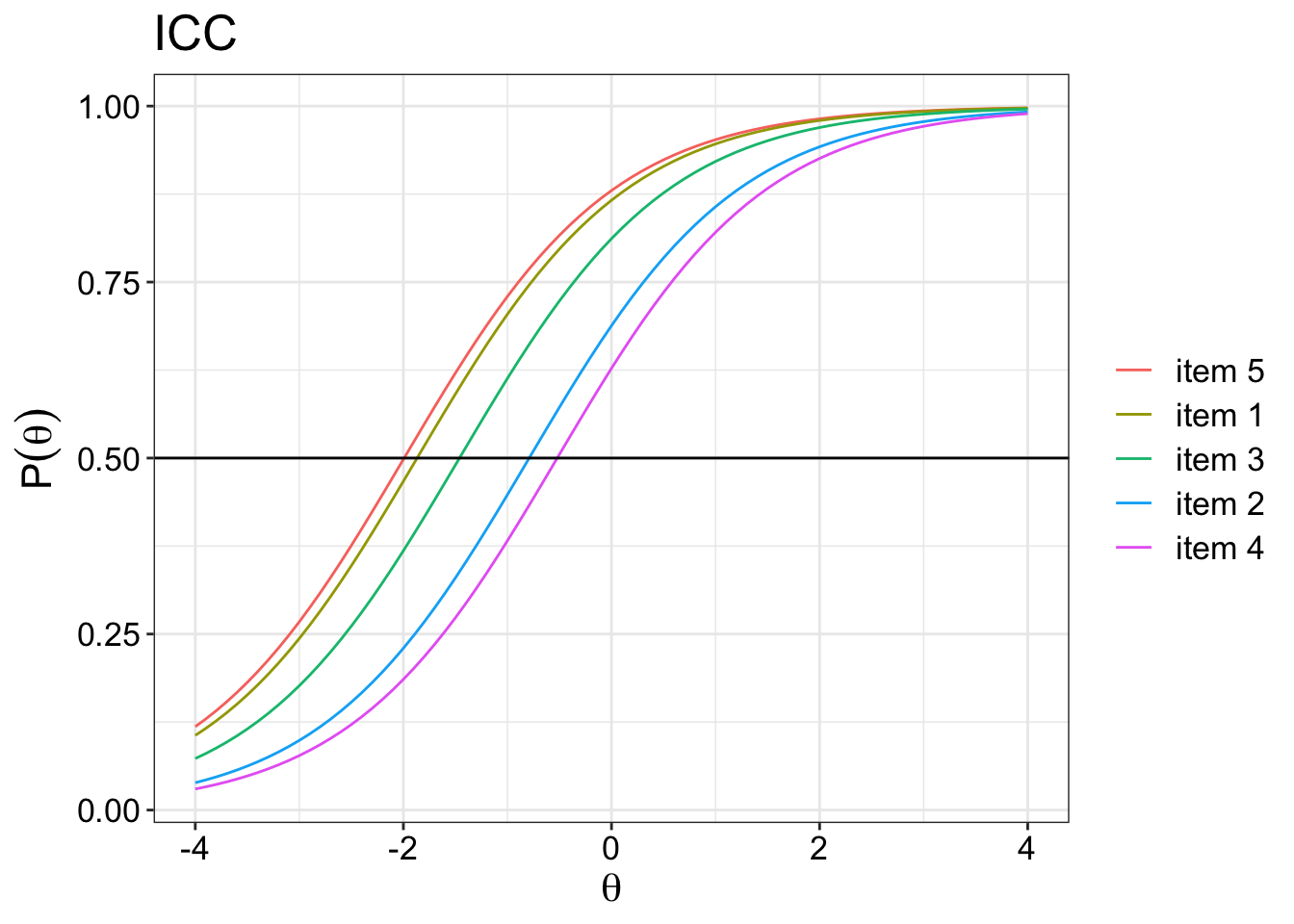
Dichotomous response options
The difficulty parameter is used to describe how difficulty an item is to achieve a 0.5 probability of correct response at a given ability. Therefore, if the 50% chance of correctly answering an item is at the right side of the plot, then it means that a higher level of ability is needed to achieve that goal. Here you can see that item 5 is easier than item 4 because it requires a lower level of theta ability to get a 50% chance of answering an item correctly.
Polytomous response options
In the health setting, the location parameter is used instead of difficulty. Because there are far more response options in a health questionnaire (e.g. 4 response options), the categorical response curves for an item are used instead. That is, a patient with a higher level of ability, say depression, would be more likely to have a 50% probability of endorsing the most severse response options than a patient with a lower level of ability.
The categorical response curve shows the probability of each response against the theta value that measures the location of the latent trait. In other words, they represent the probability that an individual responds in a particularly category given a trait level. Just a note that, at any fixed value of ability, the sum of the response probabilities is equal to 1.0.
The points where the curves cut each other represents the transition moving from one category to the next. So patients with a theta value of less than -3 will most likely select category 1. Those between greater than -3 and -1.8 will select category 2, so on and so forth. For polytomous items (more than 2 response options), it is very complex to put them all the item curves in a single plot. So each plot represents an item.
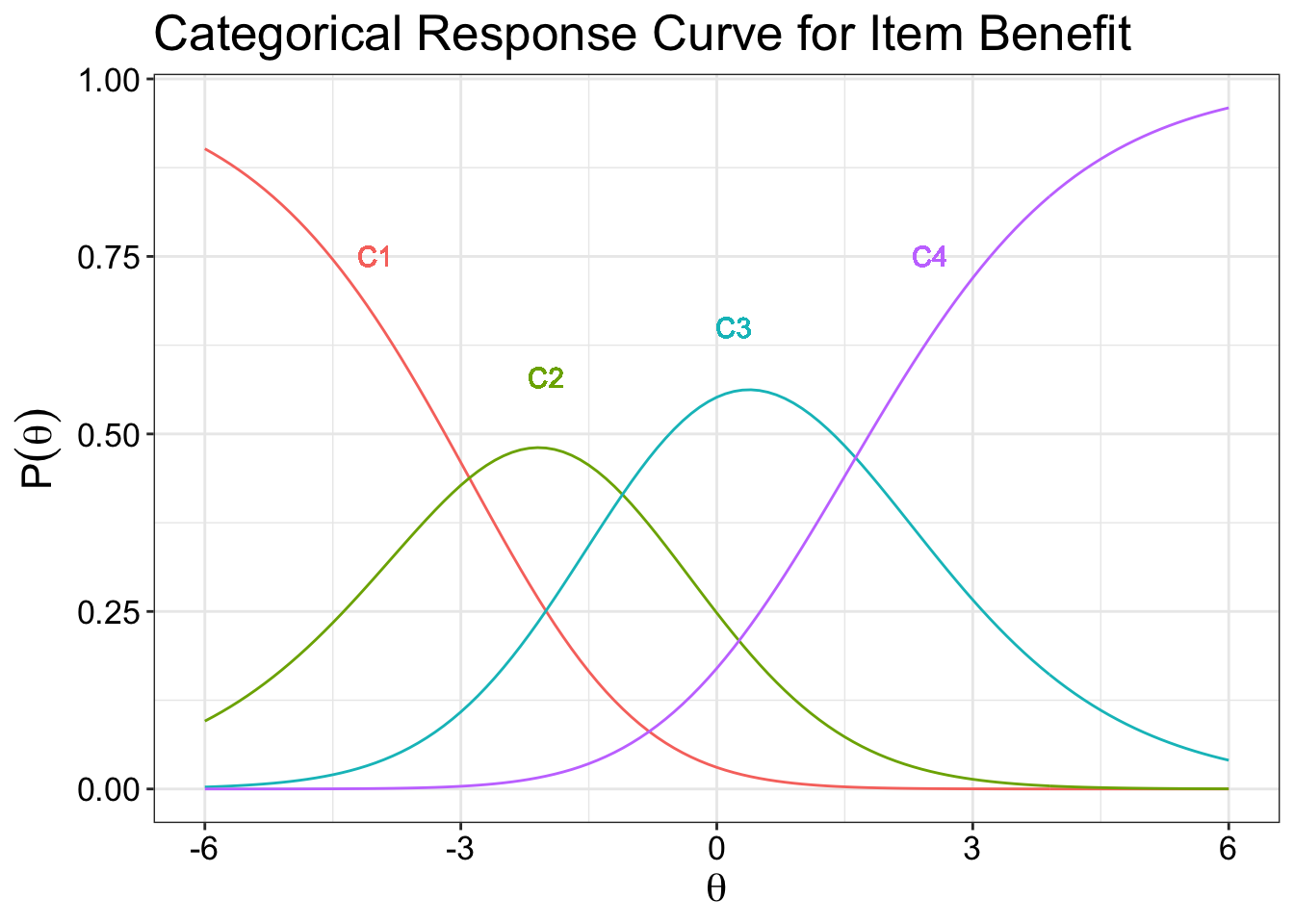
The point of between category threshold parameters represent the point (\(b_{ij}\)) along the latent trait scale at which the participants have a 0.5 probability of responding in or above a category threshold. The value for that point is known as the difficulty parameter between the two categories. So if you have 4 response option, you have 3 categories (k - 1, where k is the number of categories).
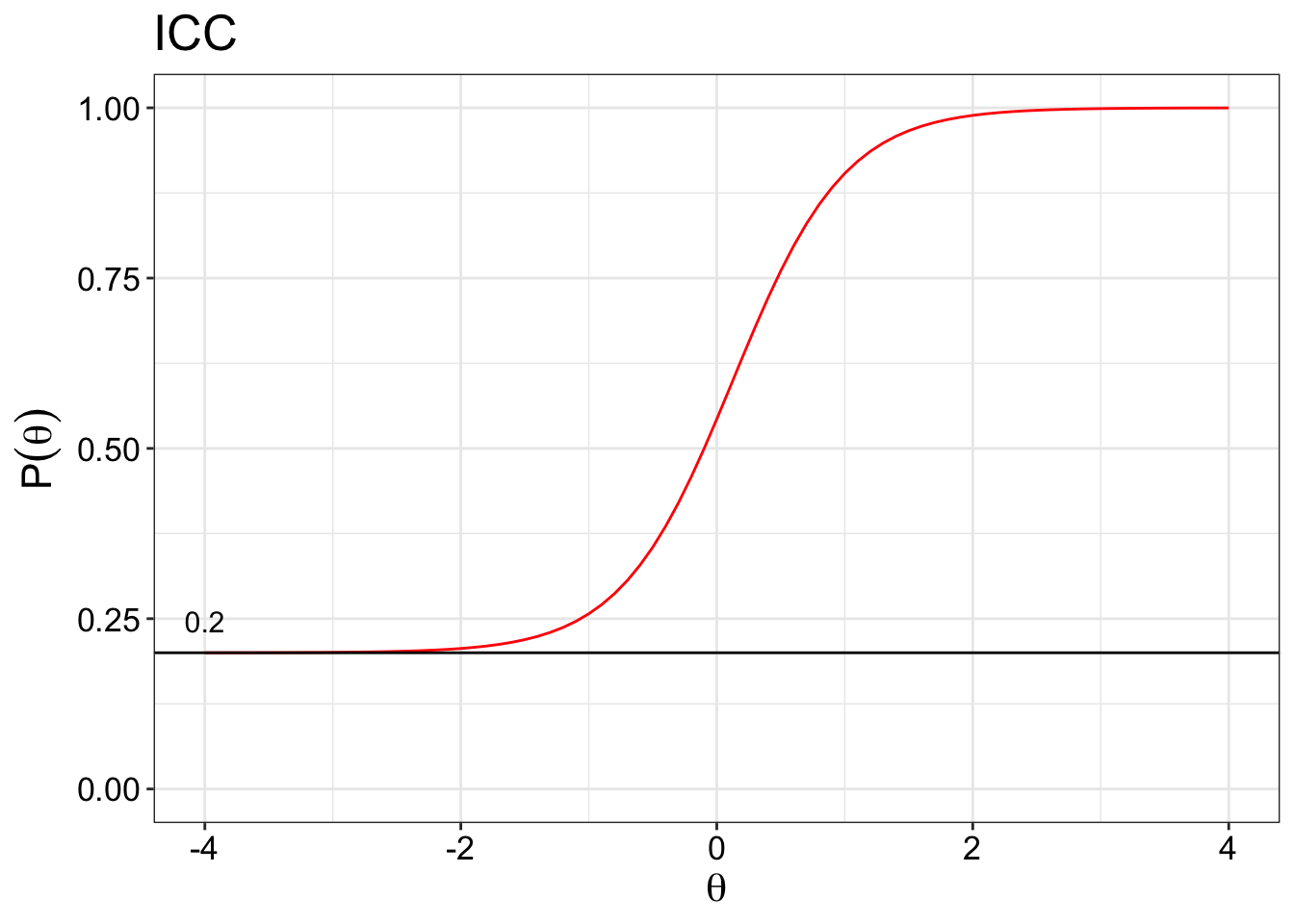
Guessing parameter (\(c_i\))
The guessing parameter is more widely used in the educational setting where guessing the correct answer for an item may be attempted by the test taker. So the IRT model has to account for the guessing or the pseudo-chance-level paramter (\(c_i\)). The plot below shows that we set a global guessing parameter to be 0.2 for all items. For example, the guessing parameter is set to 0.2 because there are 5 response options, so a 0.2 chance of randomly guessing the item correctly. It is possible to get the IRT model to get the guessing parameter as well.
This parameter is not so widely used in the health area or personality assessment since there are usually no right or wrong answers.
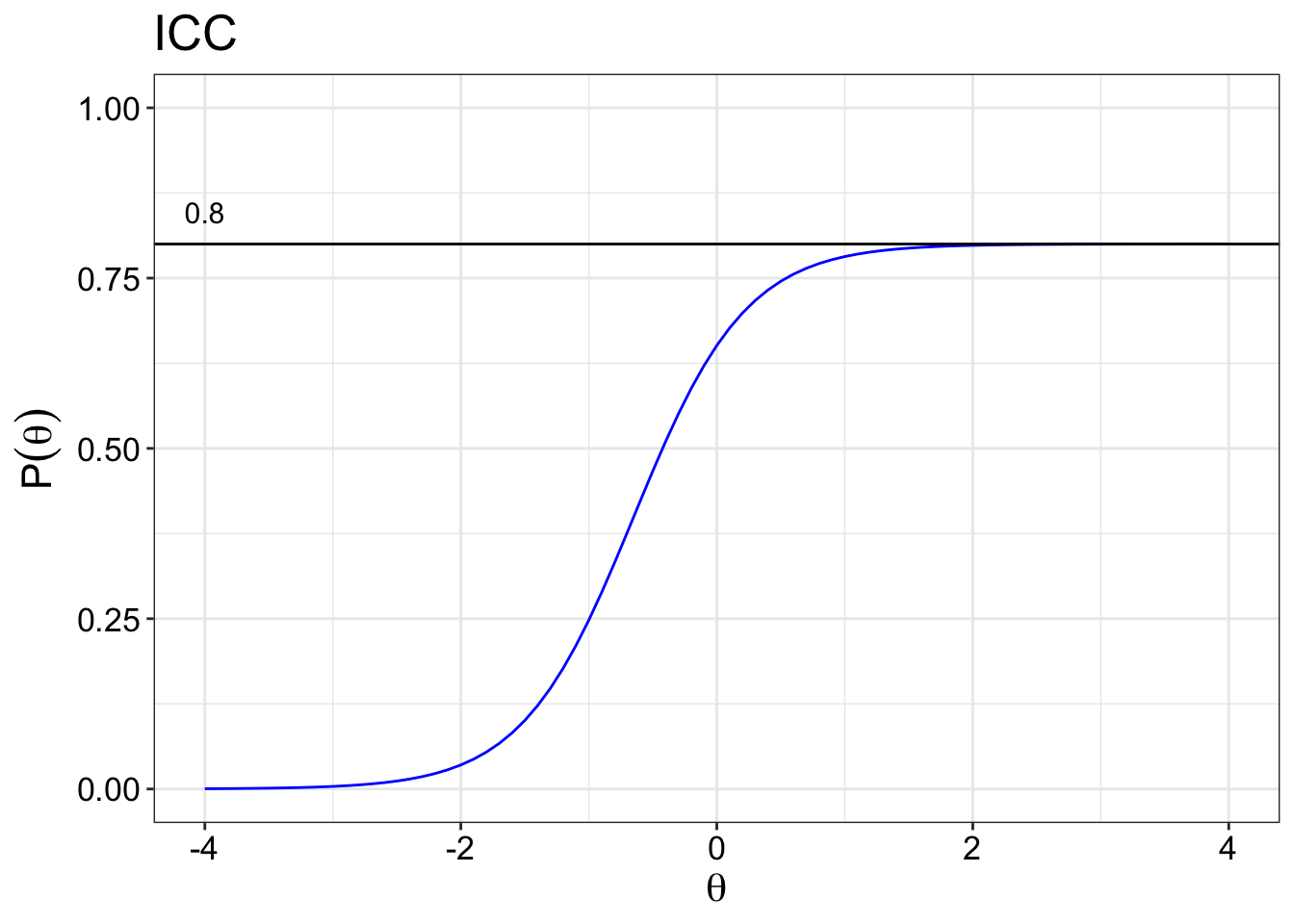
Inattention parameter (\(d_i\))
The inattention parameter is included when we want to account for situations where someone may have answered incorrectly unintentionally. This could be reasons such as fatigue, accidently clicking on the wrong response option etc. We set an arbitrary upper value of 0.8.
Again, not so widely use in psychological assessment.
Scaling factor: D constant
The scaling factor is a constant with the value of 1.7 that is used to bring the estimates of the logistic function and the normnal ogive function in an IRT model to be similar. The logistic function was introduced by Brinbaum to make it easier to calculate item parameters and the probability of theta without too much mathematical complications. The normal ogive function on the other hand, is based on the cumulative normal distribution. Nowadays, the logistic models are more widely used than the normal ogive models.
IRT Models
There are many different IRT models. I will just list the popular ones here for now. I also included the LLTM(s) because I have used them previously. IRT models that include reaction time is not within the scope for now.
Dichotomous Model
Rasch model
1 parameter logistic model
2 parameter logistic model
3 parameter logistic model
4 parameter logistic model
Unfolding model (aka Ideal point model)
Polytomous Model
Polytmous Rasch Model
Partial Credit Model
Generalised Partial Credit Model
Graded Response Model
Specialised Model
Linear Logistic Test Model (LLTM)
LLTM + error
Random weights LLTM
General Information
Sample size
The more the merrier is the answer really. There is no gold standard or magic number (Morizot et al, 2007, p.411)
Here are certain guidelines:
Dichotomous response formats.
Rasch (At least 100)
2PL (At least 250, but best is at least 500).
3PL (At least 1000) [De Ayala, 2013]
Polytomous response formats
GRM (At least 250, but 500 for accurate parameter estimates) [Reeve & Fayers, 2005, p.71]
PCM (At least 500 - 1000, based on RMSEs comparisons) [He & Wheadon, 2013]
Embretson and Reise (2000) recommended that the focus should be on the size of the standard error of item parameter estimates.
Root mean square errors (RMSEs) reflect the variation of sample parameter estimates within replications for a specific size class. When the sample size is 150, the RMSEs for some categories are as high as 0.90 logits. The RMSEs for most of the categories stay within 0.20 logits when the sample size increases to greater than 1000. (See Qing Ping He & Christopher Wheadon, 2013 for a more detailed discussion)
\(\alpha{}\) par to std loading
To convert a discrimination parameter into a value that is similar to a standardised factor loading.
The formula is :
Bear in mind that \(\alpha = \frac{\alpha}{1.702}\) because you are scaling the logistic metric to a normal ogive.
For example, if \(\alpha = 0.5\) which is \(0.5/1.702 = 0.293772\),
Then the standardised loading is:
The result is 0.2818 \(\approx\) 0.3.
Assessing goodness of fit for IRT models
The goodness-of-fit of tests cannot be computed if there are lesser distinct variances and covariances than the number of estimated parameters.
This is because we get a negative degrees of freedom.
We can use \(t = \frac{p(p+1)}{2}\) to calculate the distinct variances and covariances.
The number of estimated parameters is dependent on the total number of response options (no. of items * no. of response options).
For e.g. if we have 4 items with 7 response options. Then the distinct variances and covariances is:
The number of estimated parameters is:
Thus, 10 - 28 = -18, which results in a negative df.
Only the fit of more constrained IRT models with less than 10 parameters can be tested using covariances.
Alternatively, one may also collapse categories prior to the analysis to reduce the number of estimated parameters.
see (Maydeu-Olivares, Cai & Hernándex, 2011, pg. 340) for more discussion on this.
Citations
Chalmers, R. P. (2012). mirt: A multidimensional item response theory package for the R environment. Journal of Statistical Software, 48(6), 1-29.
De Ayala, R. J. (2013). Theory and practice of item response theory. Guilford Publications.
Embretson, S. E., & Reise, S. P. (2013). Item response theory. Psychology Press.
He, Q., & Wheadon, C. (2013). The effect of sample size on item parameter estimation for the partial credit model. International Journal of Quantitative Research in Education, 1(3), 297-315.
Maydeu-Olivares, A., Cai, L., & Hernández, A. (2011). Comparing the fit of item response theory and factor analysis models. Structural Equation Modeling: A Multidisciplinary Journal, 18(3), 333-356.
Morizot, J., Ainsworth, A. T., & Reise, S. P. (2007). Toward modern psychometrics: Application of item response theory models in personality research. In R. W. Robins, R. C. Fraley, & R. F. Krueger (Eds.), Handbook of Research Methods in Personality Psychology (pp. 407-423). New York: Guilford.
Reckase, M. (2009). Multidimensional item response theory (Vol. 150). New York, NY: Springer.
Reeve, B. B., & Fayers, P. (2005). Applying item response theory modeling for evaluating questionnaire item and scale properties. In P. Fayers & R. D. Hays (Eds.), Assessing quality of life in clinical trials: Methods of practice (2nd ed). New York: Oxford University Press, 2005. p. 55–73.
Wirth, R. J., & Edwards, M. C. (2007). Item factor analysis: current approaches and future directions. Psychological methods, 12(1), 58.
Yang, F. M. (2014). Item response theory for measurement validity. Shanghai archives of psychiatry, 26(3), 171.